


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
NFAT2 (NFATC1) (NM_172390) Human Tagged ORF Clone
CAT#: RC211136

NFATC1 (Myc-DDK-tagged)-Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1
ORF Plasmid: tGFP
Lentiviral Particles: DDK DDK w/ Puro mGFP mGFP w/ Puro
"NM_172390" in other vectors (6)
Product Images

 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC211136 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
. The protein was produced from HEK293T cells transfected with NFATC1 cDNA clone (Cat# RC211136) using MegaTran 2.0 (Cat# TT210002).")
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | NFAT2 |
| Synonyms | NF-ATC; NF-ATc1.2; NFAT2; NFATc |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC211136 ORF sequence
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGCCAAGCACCAGCTTTCCAGTCCCTTCCAAGTTTCCACTTGGCCCTGCGGCTGCGGTCTTCGGGAGAG GAGAAACTTTGGGGCCCGCGCCGCGCGCCGGCGGCACCATGAAGTCAGCGGAGGAAGAACACTATGGCTA TGCATCCTCCAACGTCAGCCCCGCCCTGCCGCTCCCCACGGCGCACTCCACCCTGCCGGCCCCGTGCCAC AACCTTCAGACCTCCACACCGGGCATCATCCCGCCGGCGGATCACCCCTCGGGGTACGGGGCAGCTTTGG ACGGTGGGCCCGCGGGCTACTTCCTCTCCTCCGGCCACACCAGGCCTGATGGGGCCCCTGCCCTGGAGAG TCCTCGCATCGAGATAACCTCGTGCTTGGGCCTGTACCACAACAATAACCAGTTTTTCCACGATGTGGAG GTGGAAGACGTCCTCCCTAGCTCCAAACGGTCCCCCTCCACGGCCACGCTGAGTCTGCCCAGCCTGGAGG CCTACAGAGACCCCTCGTGCCTGAGCCCGGCCAGCAGCCTGTCCTCCCGGAGCTGCAACTCAGAGGCCTC CTCCTACGAGTCCAACTACTCGTACCCGTACGCGTCCCCCCAGACGTCGCCATGGCAGTCTCCCTGCGTG TCTCCCAAGACCACGGACCCCGAGGAGGGCTTTCCCCGCGGGCTGGGGGCCTGCACACTGCTGGGTTCCC CGCGGCACTCCCCCTCCACCTCGCCCCGCGCCAGCGTCACTGAGGAGAGCTGGCTGGGTGCCCGCTCCTC CAGACCCGCGTCCCCGTGCAACAAGAGGAAGTACAGCCTCAACGGCCGGCAGCCGCCCTACTCACCCCAC CACTCGCCCACGCCGTCCCCGCACGGCTCCCCGCGGGTCAGCGTGACCGACGACTCGTGGTTGGGCAACA CCACCCAGTACACCAGCTCGGCCATCGTGGCCGCCATCAACGCGCTGACCACCGACAGCAGCCTGGACCT GGGAGATGGCGTCCCTGTCAAGTCCCGCAAGACCACCCTGGAGCAGCCGCCCTCAGTGGCGCTCAAGGTG GAGCCCGTCGGGGAGGACCTGGGCAGCCCCCCGCCCCCGGCCGACTTCGCGCCCGAAGACTACTCCTCTT TCCAGCACATCAGGAAGGGCGGCTTCTGCGACCAGTACCTGGCGGTGCCGCAGCACCCCTACCAGTGGGC GAAGCCCAAGCCCCTGTCCCCTACGTCCTACATGAGCCCGACCCTGCCCGCCCTGGACTGGCAGCTGCCG TCCCACTCAGGCCCGTATGAGCTTCGGATTGAGGTGCAGCCCAAGTCCCACCACCGAGCCCACTACGAGA CGGAGGGCAGCCGGGGGGCCGTGAAGGCGTCGGCCGGAGGACACCCCATCGTGCAGCTGCATGGCTACTT GGAGAATGAGCCGCTGATGCTGCAGCTTTTCATTGGGACGGCGGACGACCGCCTGCTGCGCCCGCACGCC TTCTACCAGGTGCACCGCATCACAGGGAAGACCGTGTCCACCACCAGCCACGAGGCCATCCTCTCCAACA CCAAAGTCCTGGAGATCCCACTCCTGCCGGAGAACAGCATGCGAGCCGTCATTGACTGTGCCGGAATCCT GAAACTCAGAAACTCCGACATTGAACTTCGGAAAGGAGAGACGGACATCGGGAGGAAGAACACACGGGTA CGGCTGGTGTTCCGCGTTCACGTCCCGCAACCCAGCGGCCGCACGCTGTCCCTGCAGGTGGCCTCCAACC CCATCGAATGCTCCCAGCGCTCAGCTCAGGAGCTGCCTCTGGTGGAGAAGCAGAGCACGGACAGCTATCC GGTCGTGGGCGGGAAGAAGATGGTCCTGTCTGGCCACAACTTCCTGCAGGACTCCAAGGTCATTTTCGTG GAGAAAGCCCCAGATGGCCACCATGTCTGGGAGATGGAAGCGAAAACTGACCGGGACCTGTGCAAGCCGA ATTCTCTGGTGGTTGAGATCCCGCCATTTCGGAATCAGAGGATAACCAGCCCCGTTCACGTCAGTTTCTA CGTCTGCAACGGGAAGAGAAAGCGAAGCCAGTACCAGCGTTTCACCTACCTTCCCGCCAACGGTAACGCC ATCTTTCTAACCGTAAGCCGTGAACATGAGCGCGTGGGGTGCTTTTTC AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCC TGGATTACAAGGATGACGACGATAAGGTTTAA >RC211136 protein sequence
Red=Cloning site Green=Tags(s) MPSTSFPVPSKFPLGPAAAVFGRGETLGPAPRAGGTMKSAEEEHYGYASSNVSPALPLPTAHSTLPAPCH NLQTSTPGIIPPADHPSGYGAALDGGPAGYFLSSGHTRPDGAPALESPRIEITSCLGLYHNNNQFFHDVE VEDVLPSSKRSPSTATLSLPSLEAYRDPSCLSPASSLSSRSCNSEASSYESNYSYPYASPQTSPWQSPCV SPKTTDPEEGFPRGLGACTLLGSPRHSPSTSPRASVTEESWLGARSSRPASPCNKRKYSLNGRQPPYSPH HSPTPSPHGSPRVSVTDDSWLGNTTQYTSSAIVAAINALTTDSSLDLGDGVPVKSRKTTLEQPPSVALKV EPVGEDLGSPPPPADFAPEDYSSFQHIRKGGFCDQYLAVPQHPYQWAKPKPLSPTSYMSPTLPALDWQLP SHSGPYELRIEVQPKSHHRAHYETEGSRGAVKASAGGHPIVQLHGYLENEPLMLQLFIGTADDRLLRPHA FYQVHRITGKTVSTTSHEAILSNTKVLEIPLLPENSMRAVIDCAGILKLRNSDIELRKGETDIGRKNTRV RLVFRVHVPQPSGRTLSLQVASNPIECSQRSAQELPLVEKQSTDSYPVVGGKKMVLSGHNFLQDSKVIFV EKAPDGHHVWEMEAKTDRDLCKPNSLVVEIPPFRNQRITSPVHVSFYVCNGKRKRSQYQRFTYLPANGNA IFLTVSREHERVGCFF SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
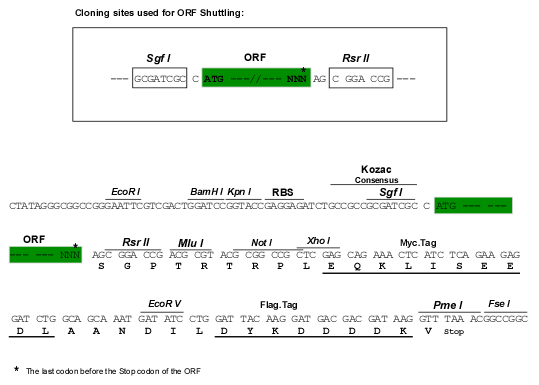
| Restriction Sites |
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_172390 |
| ORF Size | 2148 bp |
| OTI Disclaimer | Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at custsupport@origene.com or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_172390.3 |
| RefSeq Size | 2978 bp |
| RefSeq ORF | 2151 bp |
| Locus ID | 4772 |
| UniProt ID | O95644 |
| Cytogenetics | 18q23 |
| Protein Families | Druggable Genome, Transcription Factors |
| Protein Pathways | Axon guidance, B cell receptor signaling pathway, Natural killer cell mediated cytotoxicity, T cell receptor signaling pathway, VEGF signaling pathway, Wnt signaling pathway |
| MW | 77.8 kDa |
| Gene Summary | The product of this gene is a component of the nuclear factor of activated T cells DNA-binding transcription complex. This complex consists of at least two components: a preexisting cytosolic component that translocates to the nucleus upon T cell receptor (TCR) stimulation, and an inducible nuclear component. Proteins belonging to this family of transcription factors play a central role in inducible gene transcription during immune response. The product of this gene is an inducible nuclear component. It functions as a major molecular target for the immunosuppressive drugs such as cyclosporin A. Multiple alternatively spliced transcript variants encoding distinct isoforms have been identified for this gene. Different isoforms of this protein may regulate inducible expression of different cytokine genes. [provided by RefSeq, Jul 2013] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC211136L1 | Lenti ORF clone of Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1, Myc-DDK-tagged |
USD 1,283.00 |
|
| RC211136L2 | Lenti ORF clone of Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1, mGFP tagged |
USD 1,283.00 |
|
| RC211136L3 | Lenti ORF clone of Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1, Myc-DDK-tagged |
USD 1,283.00 |
|
| RC211136L4 | Lenti ORF clone of Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1, mGFP tagged |
USD 1,283.00 |
|
| RG211136 | NFATC1 (tGFP-tagged) - Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1 |
USD 1,183.00 |
|
| SC101076 | NFATC1 (untagged)-Human nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 1 (NFATC1), transcript variant 1 |
USD 985.00 |
{0} Product Review(s)
Be the first one to submit a review

