


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
ZNF423 (NM_015069) Human Tagged ORF Clone
CAT#: RC218703

ZNF423 (Myc-DDK-tagged)-Human zinc finger protein 423 (ZNF423)
ORF Plasmid: tGFP
Lentiviral Particles: DDK DDK w/ Puro mGFP mGFP w/ Puro
"NM_015069" in other vectors (6)
Product Images

 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC218703 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
USD 198.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | ZNF423 |
| Synonyms | Ebfaz; hOAZ; JBTS19; NPHP14; OAZ; Roaz; Zfp104; ZFP423 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC218703 representing NM_015069.
Blue=ORF Red=Cloning site Green=Tag(s) GCTCGTTTAGTGAACCGTCAGAATTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTG GATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCC ATGCATAAGAAGAGGGTTGAAGAGGGGGAGGCCTCAGACTTCTCGCTGGCCTGGGATTCCTCCGTGACA GCAGCAGGAGGCCTAGAAGGAGAGCCAGAGTGCGATCAGAAAACCAGCCGTGCGCTGGAAGACAGGAAC AGCGTGACAAGTCAAGAGGAGAGAAATGAGGATGATGAAGACATGGAGGATGAATCAATTTACACCTGC GATCACTGTCAGCAGGACTTCGAGTCTCTGGCAGACCTGACGGACCACCGGGCCCACCGCTGTCCTGGA GATGGTGATGACGACCCACAACTCTCCTGGGTGGCCTCGTCTCCCTCCAGCAAGGATGTTGCGTCACCC ACGCAGATGATCGGAGATGGTTGTGACCTCGGCCTCGGCGAGGAGGAAGGGGGCACGGGCCTGCCATAC CCTTGCCAGTTCTGCGACAAGTCCTTCATCCGCTTGAGCTACTTGAAGAGGCACGAGCAGATCCACAGC GACAAGCTGCCGTTCAAGTGCACCTACTGCAGCCGCCTCTTCAAGCACAAGAGGAGCCGCGACCGGCAC ATCAAGCTGCATACGGGCGACAAGAAGTATCACTGCCACGAGTGCGAGGCAGCCTTCTCCCGCAGCGAC CACCTCAAGATCCACCTGAAGACCCACAGCTCCAGCAAGCCCTTCAAGTGCACTGTGTGCAAGCGCGGC TTCTCCTCCACCAGCTCGCTGCAGAGCCACATGCAGGCCCACAAAAAGAACAAGGAGCATCTGGCCAAG TCGGAGAAGGAAGCCAAGAAGGACGACTTCATGTGCGACTACTGCGAGGACACCTTCAGCCAGACGGAG GAGCTGGAGAAGCACGTGCTCACCCGCCACCCGCAGCTGTCCGAGAAGGCGGACCTGCAGTGCATTCAC TGCCCTGAGGTCTTCGTCGACGAGAACACACTGCTCGCCCATATCCACCAAGCCCACGCCAACCAGAAA CACAAGTGCCCCATGTGCCCTGAGCAGTTCTCCTCAGTGGAAGGTGTCTACTGCCACCTGGACAGCCAC CGGCAGCCCGACTCCAGCAACCACAGTGTCAGTCCCGACCCTGTACTGGGCAGCGTGGCCTCCATGAGC AGCGCCACACCCGACTCCAGCGCCTCTGTGGAGCGTGGCTCCACCCCGGACTCCACCTTGAAGCCGCTG CGGGGGCAGAAGAAGATGCGGGATGACGGGCAGGGCTGGACCAAGGTGGTCTATAGCTGCCCCTATTGT TCCAAGCGGGACTTTAACAGCCTGGCCGTGCTGGAGATCCACCTGAAGACCATCCACGCGGACAAGCCC CAGCAGAGCCACACATGTCAGATCTGCCTGGACTCCATGCCCACCCTCTACAACCTCAACGAGCACGTT CGCAAGCTGCACAAGAACCATGCCTACCCTGTGATGCAGTTTGGCAACATCTCTGCCTTCCACTGCAAC TACTGCCCCGAGATGTTCGCCGACATCAATAGCCTGCAGGAGCACATCCGCGTCTCCCACTGCGGCCCC AACGCCAACCCCTCTGACGGTAATAATGCTTTCTTCTGCAACCAGTGCTCCATGGGTTTCCTTACTGAG TCCTCCCTCACCGAGCACATCCAGCAGGCCCACTGCAGTGTGGGCAGTGCCAAACTAGAGTCTCCGGTG GTGCAGCCCACGCAGTCCTTCATGGAGGTCTATTCCTGCCCCTACTGCACCAACTCCCCCATCTTTGGC TCCATCCTGAAACTCACCAAGCACATCAAGGAGAACCACAAGAACATTCCACTGGCCCACAGCAAGAAG TCCAAGGCCGAGCAGAGCCCAGTCTCGTCCGATGTGGAGGTGTCTTCCCCGAAGCGGCAGCGGCTCTCA GCAAGCGCCAACTCCATCTCCAATGGGGAGTATCCTTGCAATCAATGCGACCTCAAGTTCTCCAACTTT GAGAGCTTCCAGACCCACCTGAAGCTGCACCTGGAGCTGCTGCTGCGGAAGCAAGCGTGCCCCCAGTGC AAAGAGGACTTTGACTCCCAGGAGTCCCTCCTGCAGCACCTGACAGTGCATTACATGACCACGTCGACC CACTATGTGTGCGAGAGCTGCGACAAGCAATTTTCCTCGGTGGATGACCTGCAGAAGCACCTGCTGGAC ATGCACACCTTTGTGTTGTACCACTGCACCCTGTGTCAGGAGGTCTTCGACTCCAAGGTGTCCATCCAG GTGCACCTGGCGGTGAAGCACAGCAATGAGAAGAAGATGTACCGCTGCACGGCCTGCAACTGGGACTTC CGCAAGGAGGCTGACCTGCAGGTGCACGTCAAACACAGCCACCTGGGCAACCCGGCCAAGGCTCACAAG TGCATCTTCTGTGGGGAGACCTTCAGCACCGAGGTGGAGCTGCAGTGCCACATCACCACACACAGCAAG AAGTATAACTGTAAGTTCTGCAGCAAGGCCTTCCACGCCATCATCCTGCTGGAGAAGCACCTGCGGGAG AAGCACTGTGTGTTTGATGCTGCGACCGAGAACGGCACGGCCAATGGGGTACCCCCAATGGCCACCAAG AAAGCTGAGCCTGCTGACCTGCAGGGCATGCTGCTTAAGAACCCTGAGGCACCTAACAGCCATGAGGCC AGCGAGGATGACGTGGACGCGTCGGAGCCCATGTACGGCTGTGACATCTGCGGGGCGGCCTACACCATG GAGGTGCTGCTGCAGAATCACCGGCTGCGGGACCACAATATCCGGCCGGGCGAGGATGATGGCTCACGC AAGAAGGCTGAGTTTATCAAGGGCAGTCACAAGTGCAACGTTTGTTCACGGACTTTCTTCTCGGAGAAC GGGCTACGGGAGCACCTGCAGACGCACCGGGGCCCTGCCAAGCACTACATGTGTCCCATCTGTGGTGAG CGCTTCCCTTCGCTGCTGACGCTCACCGAACACAAGGTGACCCACAGCAAGAGCCTGGACACGGGCACC TGTCGCATCTGCAAGATGCCCCTGCAGAGCGAGGAGGAGTTTATTGAGCACTGCCAGATGCACCCTGAC CTGCGCAACTCACTCACGGGCTTCCGCTGTGTGGTCTGCATGCAGACAGTCACTTCCACGCTTGAGCTC AAGATCCATGGCACCTTCCACATGCAGAAGCTGGCGGGCAGCTCAGCGGCGTCCTCCCCCAATGGCCAG GGGCTGCAGAAGCTCTACAAGTGCGCCCTGTGCCTCAAGGAGTTCCGCAGCAAGCAGGACCTGGTGAAG CTTGACGTCAATGGGCTGCCCTACGGCCTCTGCGCCGGCTGCATGGCCCGCAGCGCCAACGGACAGGTG GGTGGCCTGGCCCCGCCCGAGCCCGCCGACCGGCCCTGTGCCGGCCTCCGTTGCCCCGAGTGCAGTGTC AAGTTTGAGAGTGCCGAAGACCTGGAGAGCCACATGCAGGTGGACCACCGTGACCTCACGCCGGAGACC AGTGGGCCCCGGAAAGGCACCCAGACATCGCCAGTGCCCCGGAAAAAGACATACCAGTGCATCAAGTGC CAGATGACCTTCGAGAACGAGAGAGAGATCCAAATCCACGTTGCCAACCACATGATTGAGGAAGGCATC AACCACGAGTGTAAGCTGTGCAACCAGATGTTCGACTCCCCGGCCAAGCTCCTCTGTCACCTCATTGAG CACAGCTTCGAGGGCATGGGCGGCACCTTCAAATGCCCCGTGTGTTTCACAGTCTTCGTCCAGGCCAAC AAGTTGCAGCAGCACATCTTTGCCGTGCACGGGCAGGAGGACAAGATCTACGACTGCTCACAGTGCCCT CAGAAGTTCTTCTTCCAGACCGAGCTGCAGAACCACACGATGAGCCAGCACGCACAGAG AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGAT ATCCTGGATTACAAGGATGACGACGATAAGGTTTAA >Peptide sequence encoded by RC218703
Blue=ORF Red=Cloning site Green=Tag(s) MHKKRVEEGEASDFSLAWDSSVTAAGGLEGEPECDQKTSRALEDRNSVTSQEERNEDDEDMEDESIYTC DHCQQDFESLADLTDHRAHRCPGDGDDDPQLSWVASSPSSKDVASPTQMIGDGCDLGLGEEEGGTGLPY PCQFCDKSFIRLSYLKRHEQIHSDKLPFKCTYCSRLFKHKRSRDRHIKLHTGDKKYHCHECEAAFSRSD HLKIHLKTHSSSKPFKCTVCKRGFSSTSSLQSHMQAHKKNKEHLAKSEKEAKKDDFMCDYCEDTFSQTE ELEKHVLTRHPQLSEKADLQCIHCPEVFVDENTLLAHIHQAHANQKHKCPMCPEQFSSVEGVYCHLDSH RQPDSSNHSVSPDPVLGSVASMSSATPDSSASVERGSTPDSTLKPLRGQKKMRDDGQGWTKVVYSCPYC SKRDFNSLAVLEIHLKTIHADKPQQSHTCQICLDSMPTLYNLNEHVRKLHKNHAYPVMQFGNISAFHCN YCPEMFADINSLQEHIRVSHCGPNANPSDGNNAFFCNQCSMGFLTESSLTEHIQQAHCSVGSAKLESPV VQPTQSFMEVYSCPYCTNSPIFGSILKLTKHIKENHKNIPLAHSKKSKAEQSPVSSDVEVSSPKRQRLS ASANSISNGEYPCNQCDLKFSNFESFQTHLKLHLELLLRKQACPQCKEDFDSQESLLQHLTVHYMTTST HYVCESCDKQFSSVDDLQKHLLDMHTFVLYHCTLCQEVFDSKVSIQVHLAVKHSNEKKMYRCTACNWDF RKEADLQVHVKHSHLGNPAKAHKCIFCGETFSTEVELQCHITTHSKKYNCKFCSKAFHAIILLEKHLRE KHCVFDAATENGTANGVPPMATKKAEPADLQGMLLKNPEAPNSHEASEDDVDASEPMYGCDICGAAYTM EVLLQNHRLRDHNIRPGEDDGSRKKAEFIKGSHKCNVCSRTFFSENGLREHLQTHRGPAKHYMCPICGE RFPSLLTLTEHKVTHSKSLDTGTCRICKMPLQSEEEFIEHCQMHPDLRNSLTGFRCVVCMQTVTSTLEL KIHGTFHMQKLAGSSAASSPNGQGLQKLYKCALCLKEFRSKQDLVKLDVNGLPYGLCAGCMARSANGQV GGLAPPEPADRPCAGLRCPECSVKFESAEDLESHMQVDHRDLTPETSGPRKGTQTSPVPRKKTYQCIKC QMTFENEREIQIHVANHMIEEGINHECKLCNQMFDSPAKLLCHLIEHSFEGMGGTFKCPVCFTVFVQAN KLQQHIFAVHGQEDKIYDCSQCPQKFFFQTELQNHTMSQHAQ SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
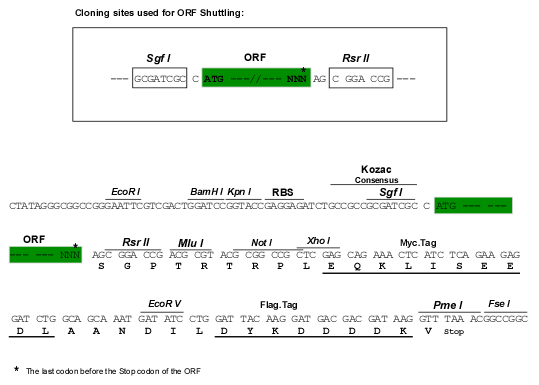
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_015069 |
| ORF Size | 3861 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq Size | 4846 bp |
| RefSeq ORF | 3855 bp |
| Locus ID | 23090 |
| UniProt ID | Q2M1K9 |
| Cytogenetics | 16q12.1 |
| Domains | zf-C2H2 |
| MW | 144.8 kDa |
| Gene Summary | The protein encoded by this gene is a nuclear protein that belongs to the family of Kruppel-like C2H2 zinc finger proteins. It functions as a DNA-binding transcription factor by using distinct zinc fingers in different signaling pathways. Thus, it is thought that this gene may have multiple roles in signal transduction during development. Mutations in this gene are associated with nephronophthisis-14 and Joubert syndrome-19. Alternatively spliced transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Oct 2012] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC218703L1 | Lenti ORF clone of Human zinc finger protein 423 (ZNF423), Myc-DDK-tagged |
USD 1,420.00 |
|
| RC218703L2 | Lenti ORF clone of Human zinc finger protein 423 (ZNF423), mGFP tagged |
USD 1,420.00 |
|
| RC218703L3 | Lenti ORF clone of Human zinc finger protein 423 (ZNF423), Myc-DDK-tagged |
USD 1,420.00 |
|
| RC218703L4 | Lenti ORF clone of Human zinc finger protein 423 (ZNF423), mGFP tagged |
USD 1,420.00 |
|
| RG218703 | ZNF423 (tGFP-tagged) - Human zinc finger protein 423 (ZNF423) |
USD 1,320.00 |
|
| SC316594 | ZNF423 (untagged)-Human zinc finger protein 423 (ZNF423) |
USD 1,118.00 |
{0} Product Review(s)
Be the first one to submit a review

