


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
CARD11 (NM_032415) Human Tagged ORF Clone
CAT#: RC222740

CARD11 (Myc-DDK-tagged)-Human caspase recruitment domain family, member 11 (CARD11)
ORF Plasmid: tGFP
Lentiviral Particles: DDK DDK w/ Puro mGFP mGFP w/ Puro
"NM_032415" in other vectors (6)
Product Images

 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC222740 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
. The protein was produced from HEK293T cells transfected with CARD11 cDNA clone (Cat# RC222740) using MegaTran 2.0 (Cat# TT210002).")
USD 198.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | CARD11 |
| Synonyms | BENTA; BIMP3; CARMA1; IMD11; IMD11A; PPBL |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC222740 representing NM_032415.
Blue=ORF Red=Cloning site Green=Tag(s) GTGAACCGTCAGAATTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCAGTA CCGAGGAGATCTGCGCCGCGATCGCCGGCGCGCCC ATGCCAGGAGGAGGGCCAGAGATGGATGACTACATGGAGACGCTGAAGGATGAAGAGGACGCCTTGTGG GAGAATGTGGAGTGTAACCGGCACATGCTCAGCCGCTATATCAACCCTGCCAAGCTCACGCCCTACCTG CGTCAGTGTAAGGTCATTGATGAGCAGGATGAAGATGAAGTGCTTAATGCCCCTATGCTGCCATCCAAG ATCAACCGAGCAGGCCGGCTGTTGGACATTCTACATACCAAGGGGCAAAGGGGCTATGTGGTCTTCTTG GAGAGCCTAGAATTTTATTACCCAGAACTGTACAAACTGGTGACTGGGAAAGAGCCCACTCGGAGATTC TCCACCATTGTGGTGGAGGAAGGCCACGAGGGCCTCACGCACTTCCTGATGAACGAGGTCATCAAGCTG CAGCAGCAGATGAAGGCCAAGGACCTGCAACGCTGCGAGCTGCTGGCCAGGTTGCGGCAGCTGGAGGAT GAGAAGAAGCAGATGACGCTGACGCGCGTGGAGCTGCTAACCTTCCAGGAGCGGTACTACAAGATGAAG GAAGAGCGGGACAGCTACAATGACGAGCTGGTCAAGGTGAAGGACGACAACTACAACTTAGCCATGCGC TACGCACAGCTCAGTGAGGAGAAGAACATGGCGGTCATGAGGAGCCGAGACCTCCAACTCGAGATCGAT CAGCTAAAGCACCGGTTGAATAAGATGGAGGAGGAATGTAAGCTGGAGAGAAATCAGTCTCTAAAACTG AAGAATGACATTGAAAATCGGCCCAAGAAGGAGCAGGTTCTGGAACTGGAGCGGGAGAATGAAATGCTG AAGACCAAAAACCAGGAGCTGCAGTCCATCATCCAGGCCGGGAAGCGCAGCCTGCCAGACTCAGACAAG GCCATCCTGGACATCTTGGAACACGACCGCAAGGAGGCCCTGGAGGACAGGCAGGAGCTGGTCAACAGG ATCTACAACCTGCAGGAGGAGGCCCGCCAGGCAGAGGAGCTGCGAGACAAGTACCTGGAGGAGAAGGAG GACCTGGAGCTCAAGTGCTCGACCCTGGGAAAGGACTGTGAAATGTACAAGCACCGCATGAACACGGTC ATGCTGCAGCTGGAGGAGGTGGAGCGGGAGCGGGACCAGGCCTTCCACTCCCGAGATGAAGCTCAGACA CAGTACTCGCAGTGCTTAATCGAAAAGGACAAGTACAGGAAGCAGATCCGCGAGCTGGAGGAGAAGAAC GATGAGATGAGGATCGAGATGGTGCGGCGGGAGGCCTGCATCGTCAACCTGGAGAGCAAGCTGCGGCGC CTCTCCAAGGACAGCAACAACCTGGACCAGAGTCTGCCCAGGAACCTGCCAGTAACCATCATCTCTCAG GACTTTGGGGATGCCAGCCCCAGGACCAATGGTCAAGAAGCTGACGATTCTTCCACCTCGGAGGAGTCA CCTGAAGACAGCAAGTACTTCCTGCCCTACCATCCGCCCCAGCGCAGGATGAACCTGAAGGGCATCCAG CTGCAGAGAGCCAAATCCCCCATCAGCCTGAAGCGAACATCAGATTTTCAAGCCAAGGGGCACGAGGAA GAAGGCACGGATGCCAGCCCTAGCTCCTGCGGATCTCTGCCCATCACCAACTCCTTCACCAAGATGCAG CCCCCCCGGAGCCGCAGCAGCATCATGTCAATCACCGCCGAGCCCCCGGGAAACGACTCCATCGTCAGA CGCTACAAGGAGGACGCGCCCCATCGCAGCACAGTCGAAGAAGACAATGACAGCGGCGGGTTTGACGCC TTAGATCTGGATGATGACAGTCACGAACGCTACTCCTTCGGACCCTCCTCCATCCACTCCTCCTCCTCC TCCCACCAATCCGAGGGCCTGGATGCCTACGACCTGGAGCAGGTCAACCTCATGTTCAGGAAGTTCTCT CTGGAAAGACCCTTCCGGCCTTCGGTCACCTCTGTGGGGCACGTGCGGGGCCCAGGGCCCTCGGTGCAG CACACGACGCTGAATGGCGACAGCCTCACCTCCCAGCTCACCCTGCTGGGGGGCAACGCGCGAGGGAGC TTCGTGCACTCGGTCAAGCCTGGCTCTCTGGCCGAGAAAGCCGGCCTCCGTGAGGGCCACCAGCTGCTG CTGCTAGAAGGCTGCATCCGAGGCGAGAGGCAGAGTGTCCCGTTGGACACATGCACCAAAGAGGAAGCC CACTGGACCATCCAGAGGTGCAGCGGCCCCGTCACGCTGCACTACAAGGTCAACCACGAAGGGTACCGG AAGCTGGTGAAGGACATGGAGGACGGCCTGATCACATCGGGGGACTCGTTCTACATCCGGCTGAACCTG AACATCTCCAGCCAGCTGGACGCCTGCACCATGTCCCTGAAGTGTGACGATGTTGTGCACGTCCGTGAC ACCATGTACCAGGACAGGCACGAGTGGCTGTGCGCGCGGGTCGACCCTTTCACAGACCATGACCTGGAT ATGGGCACCATACCCAGCTACAGCCGAGCCCAGCAGCTCCTCCTGGTGAAACTGCAGCGCCTGATGCAC CGAGGCAGCCGGGAGGAGGTAGACGGCACCCACCACACCCTGCGGGCACTCCGGAACACCCTGCAGCCA GAAGAAGCGCTTTCAACAAGCGACCCCCGGGTCAGCCCCCGTCTCTCGCGAGCAAGCTTCCTTTTTGGC CAGCTCCTTCAGTTCGTCAGCAGGTCCGAGAACAAGTATAAGCGGATGAACAGCAACGAGCGGGTCCGC ATCATCTCGGGGAGTCCGCTAGGGAGCCTGGCCCGGTCCTCGCTGGACGCCACCAAGCTCTTGACTGAG AAGCAGGAAGAGCTGGACCCTGAGAGCGAGCTGGGCAAGAACCTCAGCCTCATCCCCTACAGCCTGGTA CGCGCCTTCTACTGCGAGCGCCGCCGGCCCGTGCTCTTCACACCCACCGTGCTGGCCAAGACGCTGGTG CAGAGGCTGCTCAACTCGGGAGGTGCCATGGAGTTCACCATCTGCAAGTCAGATATCGTCACAAGAGAT GAGTTCCTCAGAAGGCAGAAGACGGAGACCATCATCTACTCCCGAGAGAAGAACCCCAACGCGTTCGAA TGCATCGCCCCTGCCAACATTGAAGCTGTGGCCGCCAAGAACAAGCACTGCCTGCTGGAGGCTGGGATC GGCTGCACAAGAGACTTGATCAAGTCCAACATCTACCCCATCGTGCTCTTCATCCGGGTGTGTGAGAAG AACATCAAGAGGTTCAGAAAGCTGCTGCCCCGACCTGAGACGGAGGAGGAGTTCCTGCGCGTGTGCCGG CTGAAGGAGAAGGAGCTGGAGGCCCTGCCGTGCCTGTACGCCACGGTGGAACCTGACATGTGGGGCAGC GTAGAGGAGCTGCTCCGCGTTGTCAAGGACAAGATCGGCGAGGAGCAGCGCAAGACCATCTGGGTGGAC GAGGACCAGCTG AGCGGTCCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGAT ATCCTGGATTACAAGGATGACGACGATAAGGTTTAA >Peptide sequence encoded by RC222740
Blue=ORF Red=Cloning site Green=Tag(s) MPGGGPEMDDYMETLKDEEDALWENVECNRHMLSRYINPAKLTPYLRQCKVIDEQDEDEVLNAPMLPSK INRAGRLLDILHTKGQRGYVVFLESLEFYYPELYKLVTGKEPTRRFSTIVVEEGHEGLTHFLMNEVIKL QQQMKAKDLQRCELLARLRQLEDEKKQMTLTRVELLTFQERYYKMKEERDSYNDELVKVKDDNYNLAMR YAQLSEEKNMAVMRSRDLQLEIDQLKHRLNKMEEECKLERNQSLKLKNDIENRPKKEQVLELERENEML KTKNQELQSIIQAGKRSLPDSDKAILDILEHDRKEALEDRQELVNRIYNLQEEARQAEELRDKYLEEKE DLELKCSTLGKDCEMYKHRMNTVMLQLEEVERERDQAFHSRDEAQTQYSQCLIEKDKYRKQIRELEEKN DEMRIEMVRREACIVNLESKLRRLSKDSNNLDQSLPRNLPVTIISQDFGDASPRTNGQEADDSSTSEES PEDSKYFLPYHPPQRRMNLKGIQLQRAKSPISLKRTSDFQAKGHEEEGTDASPSSCGSLPITNSFTKMQ PPRSRSSIMSITAEPPGNDSIVRRYKEDAPHRSTVEEDNDSGGFDALDLDDDSHERYSFGPSSIHSSSS SHQSEGLDAYDLEQVNLMFRKFSLERPFRPSVTSVGHVRGPGPSVQHTTLNGDSLTSQLTLLGGNARGS FVHSVKPGSLAEKAGLREGHQLLLLEGCIRGERQSVPLDTCTKEEAHWTIQRCSGPVTLHYKVNHEGYR KLVKDMEDGLITSGDSFYIRLNLNISSQLDACTMSLKCDDVVHVRDTMYQDRHEWLCARVDPFTDHDLD MGTIPSYSRAQQLLLVKLQRLMHRGSREEVDGTHHTLRALRNTLQPEEALSTSDPRVSPRLSRASFLFG QLLQFVSRSENKYKRMNSNERVRIISGSPLGSLARSSLDATKLLTEKQEELDPESELGKNLSLIPYSLV RAFYCERRRPVLFTPTVLAKTLVQRLLNSGGAMEFTICKSDIVTRDEFLRRQKTETIIYSREKNPNAFE CIAPANIEAVAAKNKHCLLEAGIGCTRDLIKSNIYPIVLFIRVCEKNIKRFRKLLPRPETEEEFLRVCR LKEKELEALPCLYATVEPDMWGSVEELLRVVKDKIGEEQRKTIWVDEDQL SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV Recombinant protein using RC222740 also available, TP322740 |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
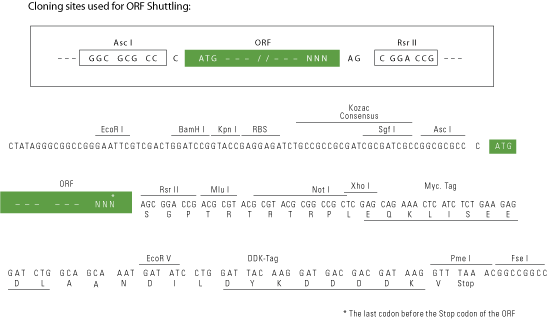
AscI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_032415 |
| ORF Size | 3462 bp |
| OTI Disclaimer | Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at custsupport@origene.com or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq Size | 4372 bp |
| RefSeq ORF | 3465 bp |
| Locus ID | 84433 |
| UniProt ID | Q9BXL7 |
| Cytogenetics | 7p22.2 |
| Protein Families | Druggable Genome |
| Protein Pathways | B cell receptor signaling pathway, T cell receptor signaling pathway |
| MW | 133.3 kDa |
| Gene Summary | The protein encoded by this gene belongs to the membrane-associated guanylate kinase (MAGUK) family, a class of proteins that functions as molecular scaffolds for the assembly of multiprotein complexes at specialized regions of the plasma membrane. This protein is also a member of the CARD protein family, which is defined by carrying a characteristic caspase-associated recruitment domain (CARD). This protein has a domain structure similar to that of CARD14 protein. The CARD domains of both proteins have been shown to specifically interact with BCL10, a protein known to function as a positive regulator of cell apoptosis and NF-kappaB activation. When expressed in cells, this protein activated NF-kappaB and induced the phosphorylation of BCL10. [provided by RefSeq, Jul 2008] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC222740L1 | Lenti ORF clone of Human caspase recruitment domain family, member 11 (CARD11), Myc-DDK-tagged |
USD 1,806.00 |
|
| RC222740L2 | Lenti ORF clone of Human caspase recruitment domain family, member 11 (CARD11), mGFP tagged |
USD 1,806.00 |
|
| RC222740L3 | Lenti ORF clone of Human caspase recruitment domain family, member 11 (CARD11), Myc-DDK-tagged |
USD 1,806.00 |
|
| RC222740L4 | Lenti ORF clone of Human caspase recruitment domain family, member 11 (CARD11), mGFP tagged |
USD 1,806.00 |
|
| RG222740 | CARD11 (tGFP-tagged) - Human caspase recruitment domain family, member 11 (CARD11) |
USD 1,706.00 |
|
| SC318529 | CARD11 (untagged)-Human caspase recruitment domain family, member 11 (CARD11) |
USD 1,508.00 |
{0} Product Review(s)
Be the first one to submit a review

