


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
GPBB (PYGB) (NM_002862) Human Tagged ORF Clone
CAT#: RC202077

PYGB (Myc-DDK-tagged)-Human phosphorylase, glycogen, brain (PYGB)
ORF Plasmid: tGFP
Lentiviral Particles: DDK w/ Puro mGFP w/ Puro
"NM_002862" in other vectors (4)
Product Images

 using anti-DDK antibody (Cat# TA50011-100). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC202077 using transfection reagent MegaTran 2.0 (Cat# TT210002).")
. The protein was produced from HEK293T cells transfected with PYGB cDNA clone (Cat# RC202077) using MegaTran 2.0 (Cat# TT210002).")
USD 198.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | GPBB |
| Synonyms | GPBB |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC202077 ORF sequence
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGCGAAGCCGCTGACGGACAGCGAGAAGCGGAAGCAGATCAGCGTGCGCGGCCTGGCGGGGCTAGGCG ACGTGGCCGAGGTGCGGAAGAGCTTCAACCGGCACTTGCACTTCACGCTGGTCAAGGACCGCAATGTGGC CACGCCCCGCGACTACTTCTTCGCGCTGGCGCACACGGTGCGCGACCACCTCGTGGGCCGCTGGATCCGC ACGCAGCAGCACTACTACGAGCGCGACCCCAAGCGCATTTATTATCTTTCCCTGGAATTCTACATGGGTC GCACGCTGCAGAACACGATGGTGAACCTGGGCCTTCAGAATGCCTGCGATGAAGCCATCTATCAGTTGGG GTTAGACTTGGAGGAACTCGAGGAGATAGAAGAAGATGCTGGCCTTGGGAATGGAGGCCTGGGGAGGCTG GCAGCGTGTTTCCTTGACTCAATGGCTACCTTGGGCCTGGCAGCATACGGCTATGGAATCCGCTATGAAT TTGGGATTTTTAACCAGAAGATTGTCAATGGCTGGCAGGTAGAGGAGGCCGATGACTGGCTGCGCTACGG CAACCCCTGGGAGAAAGCGCGGCCTGAGTATATGCTTCCCGTGCACTTCTACGGACGCGTGGAGCACACC CCCGACGGCGTGAAGTGGCTGGACACACAGGTGGTGCTGGCCATGCCCTACGACACCCCAGTGCCCGGCT ACAAGAACAACACCGTCAACACCATGCGGCTGTGGTCCGCCAAGGCTCCCAACGACTTCAAGCTGCAGGA CTTCAACGTGGGAGACTACATCGAGGCGGTCCTGGACCGGAACTTGGCTGAGAACATCTCCAGGGTCCTG TATCCAAATGATAACTTCTTTGAGGGGAAGGAGCTGCGGCTGAAGCAGGAGTACTTCGTGGTGGCCGCCA CGCTCCAGGACATCATCCGCCGCTTCAAGTCGTCCAAGTTCGGCTGCCGGGACCCTGTGAGAACCTGTTT CGAGACGTTCCCAGACAAGGTGGCCATCCAGCTGAACGACACCCACCCCGCCCTCTCCATCCCTGAGCTC ATGCGGATCCTGGTGGACGTGGAGAAGGTGGACTGGGACAAGGCCTGGGAAATCACGAAGAAGACCTGTG CATACACCAACCACACTGTGCTGCCTGAGGCCTTGGAGCGCTGGCCCGTGTCCATGTTTGAGAAGCTGCT GCCGCGGCACCTGGAGATAATCTATGCCATCAACCAGCGGCACCTGGACCACGTGGCCGCGCTGTTTCCC GGCGATGTGGACCGCCTGCGCAGGATGTCTGTGATCGAGGAGGGGGACTGCAAGCGGATCAACATGGCCC ACCTGTGTGTGATTGGGTCCCATGCTGTCAATGGTGTGGCGAGGATCCACTCGGAGATCGTGAAACAGTC GGTCTTTAAGGATTTTTATGAACTGGAGCCAGAGAAGTTCCAGAATAAGACCAATGGCATCACCCCCCGC CGGTGGCTGCTGCTGTGCAACCCGGGGCTGGCCGATACCATCGTGGAGAAAATTGGGGAGGAGTTCCTGA CTGACCTGAGCCAGCTGAAGAAGCTGCTGCCGCTGGTCAGTGACGAGGTGTTCATCAGGGACGTGGCCAA GGTCAAACAGGAGAACAAGCTCAAGTTCTCGGCCTTCCTGGAGAAGGAGTACAAGGTGAAGATCAACCCC TCCTCCATGTTCGATGTGCATGTGAAGAGGATCCACGAGTACAAGCGGCAGCTGCTCAACTGCCTGCACG TCGTCACCCTGTACAATCGAATCAAGAGAGACCCGGCCAAGGCTTTTGTGCCCAGGACTGTTATGATTGG GGGCAAGGCAGCGCCCGGTTACCACATGGCCAAGCTGATCATCAAGTTGGTCACCTCCATCGGCGACGTC GTCAATCATGACCCAGTTGTGGGTGACAGGTTGAAAGTGATCTTCCTGGAGAACTACCGTGTGTCCTTGG CTGAGAAAGTGATCCCGGCCGCTGATCTGTCGCAGCAGATCTCCACTGCAGGCACCGAGGCCTCAGGCAC AGGCAACATGAAGTTCATGCTCAACGGGGCCCTCACCATCGGCACCATGGACGGCGCCAACGTGGAGATG GCCGAGGAGGCCGGGGCCGAGAACCTCTTCATCTTCGGCCTGCGGGTGGAGGATGTCGAGGCCTTGGACC GGAAAGGGTACAATGCCAGGGAGTACTACGACCACCTGCCCGAGCTGAAGCAGGCCGTGGACCAGATCAG CAGTGGCTTTTTTTCTCCCAAGGAGCCAGACTGCTTCAAGGACATCGTGAACATGCTGATGCACCATGAC AGGTTCAAGGTGTTTGCAGACTATGAAGCCTACATGCAGTGCCAGGCACAGGTGGACCAGCTGTACCGGA ACCCCAAGGAGTGGACCAAGAAGGTCATCAGGAACATCGCCTGCTCGGGCAAGTTCTCCAGTGACCGGAC CATCACGGAGTATGCACGGGAGATCTGGGGTGTGGAGCCCTCCGACCTGCAGATCCCGCCCCCCAACATC CCCCGGGAC AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCC TGGATTACAAGGATGACGACGATAAGGTTTAA >RC202077 protein sequence
Red=Cloning site Green=Tags(s) MAKPLTDSEKRKQISVRGLAGLGDVAEVRKSFNRHLHFTLVKDRNVATPRDYFFALAHTVRDHLVGRWIR TQQHYYERDPKRIYYLSLEFYMGRTLQNTMVNLGLQNACDEAIYQLGLDLEELEEIEEDAGLGNGGLGRL AACFLDSMATLGLAAYGYGIRYEFGIFNQKIVNGWQVEEADDWLRYGNPWEKARPEYMLPVHFYGRVEHT PDGVKWLDTQVVLAMPYDTPVPGYKNNTVNTMRLWSAKAPNDFKLQDFNVGDYIEAVLDRNLAENISRVL YPNDNFFEGKELRLKQEYFVVAATLQDIIRRFKSSKFGCRDPVRTCFETFPDKVAIQLNDTHPALSIPEL MRILVDVEKVDWDKAWEITKKTCAYTNHTVLPEALERWPVSMFEKLLPRHLEIIYAINQRHLDHVAALFP GDVDRLRRMSVIEEGDCKRINMAHLCVIGSHAVNGVARIHSEIVKQSVFKDFYELEPEKFQNKTNGITPR RWLLLCNPGLADTIVEKIGEEFLTDLSQLKKLLPLVSDEVFIRDVAKVKQENKLKFSAFLEKEYKVKINP SSMFDVHVKRIHEYKRQLLNCLHVVTLYNRIKRDPAKAFVPRTVMIGGKAAPGYHMAKLIIKLVTSIGDV VNHDPVVGDRLKVIFLENYRVSLAEKVIPAADLSQQISTAGTEASGTGNMKFMLNGALTIGTMDGANVEM AEEAGAENLFIFGLRVEDVEALDRKGYNAREYYDHLPELKQAVDQISSGFFSPKEPDCFKDIVNMLMHHD RFKVFADYEAYMQCQAQVDQLYRNPKEWTKKVIRNIACSGKFSSDRTITEYAREIWGVEPSDLQIPPPNI PRD SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
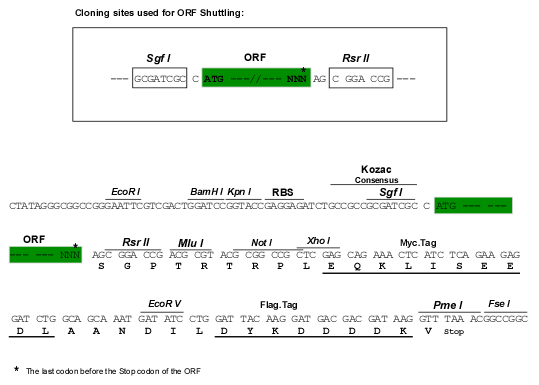
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_002862 |
| ORF Size | 2529 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_002862.4 |
| RefSeq Size | 4131 bp |
| RefSeq ORF | 2532 bp |
| Locus ID | 5834 |
| UniProt ID | P11216 |
| Cytogenetics | 20p11.21 |
| Domains | phosphorylase |
| Protein Families | Druggable Genome |
| Protein Pathways | Insulin signaling pathway, Starch and sucrose metabolism |
| MW | 96.7 kDa |
| Gene Summary | The protein encoded by this gene is a glycogen phosphorylase found predominantly in the brain. The encoded protein forms homodimers which can associate into homotetramers, the enzymatically active form of glycogen phosphorylase. The activity of this enzyme is positively regulated by AMP and negatively regulated by ATP, ADP, and glucose-6-phosphate. This enzyme catalyzes the rate-determining step in glycogen degradation. [provided by RefSeq, Jul 2008] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC202077L3 | Lenti ORF clone of Human phosphorylase, glycogen; brain (PYGB), Myc-DDK-tagged |
USD 1,072.00 |
|
| RC202077L4 | Lenti ORF clone of Human phosphorylase, glycogen; brain (PYGB), mGFP tagged |
USD 1,072.00 |
|
| RG202077 | PYGB (tGFP-tagged) - Human phosphorylase, glycogen; brain (PYGB) |
USD 972.00 |
|
| SC118380 | PYGB (untagged)-Human phosphorylase, glycogen, brain (PYGB) |
USD 773.00 |
{0} Product Review(s)
Be the first one to submit a review

