


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Col6a6 (NM_001102607) Mouse Tagged ORF Clone
CAT#: MR218404
- TrueORF®
Col6a6 (Myc-DDK-tagged) - Mouse collagen, type VI, alpha 6 (Col6a6), transcript variant 1
ORF Plasmid: tGFP
"NM_001102607" in other vectors (2)
Interest in protein/lysate? Submit request here!
Product Images

USD 198.00
Specifications
| Product Data | |
| Type | Mouse Tagged ORF Clone |
| Tag | Myc-DDK |
| Symbol | Col6a6 |
| Synonyms | E330019B14; E330026B02Rik |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>MR218404 representing NM_001102607
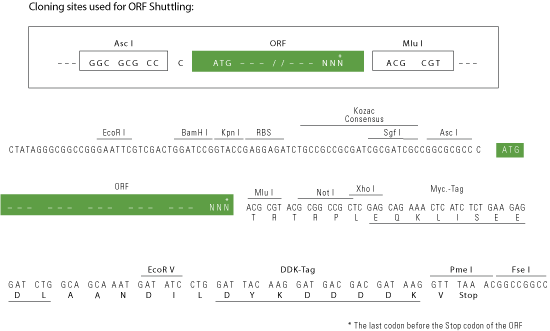
Red=Cloning site Blue=ORF Green=Tags(s) CTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCCGGCGC GCCC ATGCTGCTGGTTTTGTGCCTGACAATGATTTGTTTCCACGTGTGTGTGAACCAAGATTCTGGCCCCGAGT ACGCAGACGTGGTGTTTCTGGTGGACAGCTCCGATCACCTAGGGCTTAAGTCCTTTCCTCTTGTGAAAAC TTTCATCCACAAGATGATCAGCAGCCTCCCCATAGAGGCCAACAAGTACCGCGTGGCCCTGGCCCAGTAC AGCGATGCTCTCCACAATGAGTTCCAGCTGGGCACCTTCAAGAACAGGAACCCCATGCTGAACCACCTGA AGAAGAACTTCGGGTTCATCGGTGGCTCCCTGAAGATAGGGAACGCCCTGCAGGAGGCTCACAGGACCTA TTTCTCTGCTCCCACAAATGGAAGAGACAAGAAACAGTTCCCCCCAATCCTGGTGGTGCTGGCTTCAGCA GAGTCTGAGGATGATGTGGAAGAGGCTGCGAAGGCCCTGCGGGAAGATGGGGTGAAAATCATCTCTGTGG GGGTGCAGAAGGCTTCTGAGGAAAACCTGAAGGCGATGGCCACCTCTCAGTTCCATTTCAATCTCAGGAC TGCCAGAGACCTCAGCGTGTTTGCCCCAAACATGACAGAGATCATCAAGGATGTGACTCAGTACAGGGAA GGAATGGCAGATGACATTATTGTAGAAGCCTGCCAAGGCCCTTCTGTGGCTGATGTGGTGTTCCTGTTGG ATATGGCCATCAACGGCAGCCAGGAGGACCTAGATCATCTTAAAGCATTCCTGGGCGAAAGCATCTCTGC CCTGGACATAAAGGAAAATTGCATGAGGGTTGGCCTGGTGACCTATAGCAATGAGACAAGGGTGATCAGC TCTCTGAGCACGGGTAACAACAAGACAGAAGTCTTGCAGCGCATACAGGATCTGTCCCCTCAAGTAGGGC AGGCCTACACTGGAGCTGCCCTCAGAAAGACTAGGAAGGAAATCTTCAGTGCACAGAGGGGCAGTCGGAA GAACCAAGGGGTCCCTCAGATCGCTGTGCTGGTGACCCACAGAGCATCAGAAGACAACGTGACCAAGGCA GCTGTCAACCTCCGGCGGGAGGGAGTGACCATCTTTACCATGGGCATAGAGGGGGCTAACCCAGACGAGC TGGAGAAGATCGCATCCCACCCTGCGGAGCAGTTCACCTCCAAACTGGGCAACTTCTCTGAGCTGGCCAC CCACAACCAGACGTTCCTGAAGAAACTGCGGAACCAAATCACACACACGGTCTCTGTCTTCTCAGAACGG ACTGAGACCCTCAAATCTGCCTGTGTGGACACAGAGGAAGCCGATATCTATCTACTCATTGATGGTTCAG GGAGCACCCAGCCCACAGACTTCCATGAAATGAAGACCTTCCTGTCAGAGGTGGTAGGCATGTTCAACAT TGCTCCCCACAAGGTGCGAGTAGGGGCCGTGCAGTACGCCGACACCTGGGACTTGGAATTTGAGATCTCT AAGTATAGTAACAAGCCTGACTTGGGAAAGGCCATCGAGAATATCAGGCAGATGGGTGGGAATACCAACA CAGGGGCGGCTTTGAACTTCACACTGAAGCTGTTGCAAAGAGCAAAGAAGGAACGAGGAAGCAAAGTGCC GTGTCACCTGGTGGTTCTGACCAATGGCATGTCTCGGGACAGCGTCCTGGGGCCTGCCCATAAGCTGAGA GAGGAAAACATCAGAGTGCATGCGATCGGTGTCAAGGAAGCCAACCAAACGCAGCTTCGGGAGATAGCGG GAGAGGAAAAGCGAGTTTACTACGTCCATGAGTTCGATGCCTTGAGGAACATAAGGAACCAAGTGGTTCA GGAGATCTGTGCTGAAGAAGCCTGCAGAGACATGAAAGCGGACATCATGTTTCTGGTGGACAGCTCTGGC AGCATCGGACCTGAAAACTTCAGCAAGATGAAGATGTTTATGAAGAACCTGGTGAGCAAATCCCAGATCG GGGCTGACCGGGTGCAAATTGGCGTGGTCCAGTTCAGCCACGAAAACAAGGAGGAGTTTCAGCTCAACAC GTTCATGTCTCAAAGTGACATCGCCAACGCCATTGACCGAATGACTCACATTGGAGAAACAACCTTGACG GGCAGTGCCCTGACCTTTGTGTCTCAGTACTTCAGTCCCGATAAGGGGGCCAGGCCCAATGTCAGGAAGT TCCTCATTCTTATCACGGATGGTGAGGCTCAGGACATAGTAAGGGACCCAGCGATCGCCCTTCGAAAAGA AGGTGTGATTATCTATTCTGTGGGAGTATTCGGCTCCAATGTCACCCAGCTTGAGGAGATCAGTGGAAAG CCAGAGATGGTTTTCTATGTTGAGAATTTTGACATTCTGCAGCATATCGAAGATGACCTCGTTCTGGGGA TCTGCAGTCCCCGTGAAGAATGCAAGCGGATTGAAGTTTTGGATGTGGTGTTTGTCATCGATAGCTCCGG CAGCATTGACTATCAAGAATATAACATCATGAAGGACTTCATGATTGGCTTGGTGAAAAAAGCTGACGTG GGCAAGAATCAGGTCCGGTTTGGAGCCCTGAAGTATGCTGATGACCCCGAAGTGCTGTTTTACCTGGATG AACTAGGCACGAAGCTGGAGGTAGTTTCAGTGCTCCAGAATGACCATCCCATGGGTGGAAATACTTACAC CGCTGAGGCCCTCGCCTTCTCCGATCACATGTTCACCGAAGCCCGGGGCAGCCGTCTGCACAAGGGAGTC CCCCAAGTCCTCATTGTGATTACCGACGGGGAATCTCATGACGCAGAGAAGCTCAACACCACCGCCAAGG CCCTGAGAGACAAAGGCATTCTCGTCCTGGCTGTGGGGATTGCCGGTGCCAACAGCTGGGAGCTCTTGGC CATGGCAGGGTCAAGCGACAAGTACTACTTTGTAGAGACCTTCGGAGGCCTGAAGGGAATATTTTCCGAT GTGTCAGCCAGTGTCTGTAACTCTTCAAAAGTTGATTGTGAAATTGAAAAGGTTGACCTTGTATTCCTCA TGGATGGTTCAAACAGCATCCATCCGGATGACTTCCAGAAGATGAAGGGGTTTTTGGTGTCGGTCGTTCA AGACTTCGATGTCAGCCTCAACAGAGTCCGCATAGGCGTGGCACAGTTCAGCGACAGCTACAGGTCAGAG TTTCTGCTGGGGACGTTCACCGGGGAGAGGGAGATATCCACCCAGATTGAGGGCATCCAGCAGATCTTTG GATACACCCACATCGGAGATGCTCTCAGGAAGGTGAAGTATTACTTTCAGCCAGACATGGGCAGCAGGAT CAACGCAGGTACCCCCCAGGTGCTGCTGGTCCTCACAGATGGCCGGTCCCAAGACGAGGTAGCTCAGGCC GCCGAGGAGCTGAGACACAAAGGTGTGGACATCTACTCGGTGGGCATCGGGGATGTGGATGACCAGGAAT TGGTCCAGATCACGGGGACCGCGGAGAAAAAACTGACCGTGCATAACTTCGACGAGCTAAAAAAGGTGAA GAAAAGGATCGTTCGGAACATCTGTACCTCAGGTGGTGAGAGCAATTGCTTTGTGGATGTCGTGGTTGGA TTTGACATCTCAAGCCTGCAGAGAGGGCAGACTCTGCTCGAAGGTCAGCCTTGGATGGGATCCTACCTCC AAGACCTCTTACGTGCCATCAGCTCCCTCAATGGGGTAAGCTGTGAAGTGGGCACAGAGACTCAGGTGAG CATAGCTTTTCAAGTGACGAACGCTATGGAAAGATACCCTTCCAAGTTTGAGATCTACAGTGAGAACATA CTAAGCAGCCTGCAGGGTGTGACCGTGAATGGCCCGTCTCGCCTCAACGCCAACCTGCTGAGTTCTCTGT GGGATACGTTTCAGAATAAGTCAGCTGCTCGTGGGAAGGTGGTCCTTCTATTTTCAGATGGACTGGATGA TGGCATTGAGAAACTTGAACAGAAGTCTGATGAACTCAGGAAGGAAGGCCTGAATGCCCTCATAACCATT GCTGTGGATGGAGCTGCCGATTCCAGTGACCTGGCGGACCTCCTCTACATTGAATTTGGGAAAGGATTTG AATACAGGACACAGTTCACAATTGGAATGAGGAACCTTGGGAGTCAGCTGTCAAGGCAACTAATCAATGT TGCAGAGAGGACCTGCTGCTGTCTGCTCTGCAAGTGCACAGGAGGGGACGGCGCCATGGGGGATCCAGGC TCAGCAGGAAAAAAGGGACCCCCAGGATTCAAAGGCAGTGATGGCTACCTCGGAGAGGAGGGCATTGCTG GAGAAAGAGGAGCCTCTGGGCCAATGGGAGAGCAAGGCACGAAGGGATGCTTCGGTGCCAAAGGGCCTAA GGGAACCAGAGGACTCAGTGGAGAAGAGGGTGAAGTCGGGGAAGATGGGCTTGATGGATTAGATGGAGAA CAGGGTGACCATGGGATTCCTGGAAGAAGAGGAGAAAAGGGTGACGAGGGATCTCAGGGAAACCCAGGCA GGAGAGGGGCTGCCGGTGACCGTGGAGCAAAGGGACTGCGAGGAGATCCGGGAACTCCTGGACGTGACAG TAGCATACAAGGACCCAAGGGCTTGAAAGGAGACCTTGGAAGACAAGGCAGAAGAGGCTGGCCAGGCTCT CCTGGAACACCAGGCTCAAGAAGAAAGATGGTAGTTCATGGCCGAAGAGGACACATAGGCCCACAGGGAA ATCCAGGAACCCCGGGCCCAGATGGACTTGCAGGTTCGCCAGGACTTAGAGGCCCGCAGGGTCCAAGAGG AGAGGTCGGTGAGAAAGGAGAAAAAGGAAGTCTGGGAATGAAAGGTCCTCAGGGGCCTCCAGGACCCGGA GGACAAGCTGGGAGCCAAGGCCATTTGGGAAGCCAAGGAAACAAAGGAGAACCTGGAGACCTGGGAGAAA AGGGAGCTGCTGGCTTTCCAGGTCCTCGGGGCCTGCAGGGTGACGACGGCAGCCCGGGATATGGTAGCAT TGGCCGCAAAGGGACAAAGGGGCAAGAAGGATTCCCCGGAGAGAGTGGACTGAAGGGTGATATTGGGGAC CCTGGTGATCCAGGAGAAGCTGGTCCCAAGGGAGCCAGAGGCAAAACGGTATCTGCTGGGATTCCAGGAG AGCCGGGGTCCCCCGGGGAGCCAGGACCCCCTGGACGGAAGGGTGTGAAAGGGGCCCGAGGACTGGCTTC GTTTTCCACATGTGACCTCATTCAGTACGTGCGGGACCACAGTCCTGGCAGACATGGAAAACCTGAGTGC CCAGTGCATCCAACTGAGTTGGTGTTTGTCCTGGACCAGTCCCGGGATGTCACAGAGCAGGACTTTGAGC GAATGAAGGGGATGATGGTCTCCCTAGTTAGGGATGTCAAGGTTAGGGAGGCCAACTGCCCCGTGGGTGC CCGCGTTGCCATCCTAGCCTACAACTCCCACACCAGGCACCTCATCCGCTTCTCAGATGCCTACAGGAAG GACCAGCTGCTCACGGCGATTAAAGCTCTTCCTTATGAGAGATCCTCCGACAGCAGGGAGATTGGCAAAG CCATGAGGTTCATCTCCAGGAATGTCTTCAAGAGAACCCTTCCAGGGGCTCATGTGAGAAGAATCGCCAC GTTCTTTAGCAGTGGTCCATCGGCCGACGCCCAGACCATTACCACAGCCGCCATGGAGTTCAGTGCCCTG GACATTGTACCTGTGGTGATTGCGTTCAGCAACGTGCCCTCGGTCAAGCGCGCCTTTTCAATTGATGACA CTGGCACATTCCAAGTCATTGTGGTTCCCTCCGGGTCTGATGAAGGGCCAGCGTTAGAGAGACTCCAGCG GTGCACTTTCTGCTATGATCTATGCAAGCCGGATGCTTCGTGTGACCAAGCCAAACCACCCCCCATTCAG TCCTACCTGGACACTGCATTCCTACTGGATGGCTCTCGGCACGTGGGAAGTGCAGAGTTTGAAGACATGA GAGACTTTCTAGAGGCACTGCTAGATCACTTCGAAATCACTTCGGAGCCAGAGACATCTGTCACTGGAGA CAGGGTGGCCCTGCTGAGCCATGCCCCCCTCGACTTCCTACCCAACACCCAGAGGAGTCCGGTTAGAACT GAGTTCAACCTAACCAGCTATAGCAGTAAGCGCCTCATGAAGAGACACGTGGATCAGGCAGTCCAGCAGC TGCATGGAGATGCTTTTCTTGGCCATGCCCTCGGGTGGGCACTGGACAACGTCTTTTTAAACACCCCCAA TTTGAGACGAAACAAAGTCATATTTGTGATATCTGCTGGGGAAACCAGCCACCTGGATGCGGAAACCTTA AAGAAAGAGTCCCTACGAGCCAAATGTCATGGGTATGCCCTCTTTGTCTTTTCCTTGGGCCCTGACTGGG ATGACAAGGAACTGGAAGACCTGGCCAGCCACCCCGTAGACCAGCACTTGATCCAGCTTGGCCGAATTCA TAAACCTGACCACGGATACAGTGTGAAGTTTGTGAAGTCTTTTATAAACTCCATCAGGCATGGGATAAAC AAGTATCCACCGGTCAACCTCAAAGCCAAGTGCAACAGACTCGGCTCTAGGGATCTGAAGCCGCCCCCAC GCCAGTTTCGAAGCTTTGTTCCAGGACCACAGAAAGCCAACCTCAAAGACCACACAGCAGAGGCAGCAAA GCTCTTTCAAGATAAAAAACGCCTTTCAAGTATGCTGAAAGGGGGCAGAGCTACTATTTCAAGTCTTTCC AGAAGCACACGCTATGCCTTTAAACAGGGGAAAGAAGCAATAAAAGCCACTTCTAAACTCGGTAAACGAA GTGCC ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT ACAAGGATGACGACGATAAGGTTTAA >MR218404 representing NM_001102607
Red=Cloning site Green=Tags(s) MLLVLCLTMICFHVCVNQDSGPEYADVVFLVDSSDHLGLKSFPLVKTFIHKMISSLPIEANKYRVALAQY SDALHNEFQLGTFKNRNPMLNHLKKNFGFIGGSLKIGNALQEAHRTYFSAPTNGRDKKQFPPILVVLASA ESEDDVEEAAKALREDGVKIISVGVQKASEENLKAMATSQFHFNLRTARDLSVFAPNMTEIIKDVTQYRE GMADDIIVEACQGPSVADVVFLLDMAINGSQEDLDHLKAFLGESISALDIKENCMRVGLVTYSNETRVIS SLSTGNNKTEVLQRIQDLSPQVGQAYTGAALRKTRKEIFSAQRGSRKNQGVPQIAVLVTHRASEDNVTKA AVNLRREGVTIFTMGIEGANPDELEKIASHPAEQFTSKLGNFSELATHNQTFLKKLRNQITHTVSVFSER TETLKSACVDTEEADIYLLIDGSGSTQPTDFHEMKTFLSEVVGMFNIAPHKVRVGAVQYADTWDLEFEIS KYSNKPDLGKAIENIRQMGGNTNTGAALNFTLKLLQRAKKERGSKVPCHLVVLTNGMSRDSVLGPAHKLR EENIRVHAIGVKEANQTQLREIAGEEKRVYYVHEFDALRNIRNQVVQEICAEEACRDMKADIMFLVDSSG SIGPENFSKMKMFMKNLVSKSQIGADRVQIGVVQFSHENKEEFQLNTFMSQSDIANAIDRMTHIGETTLT GSALTFVSQYFSPDKGARPNVRKFLILITDGEAQDIVRDPAIALRKEGVIIYSVGVFGSNVTQLEEISGK PEMVFYVENFDILQHIEDDLVLGICSPREECKRIEVLDVVFVIDSSGSIDYQEYNIMKDFMIGLVKKADV GKNQVRFGALKYADDPEVLFYLDELGTKLEVVSVLQNDHPMGGNTYTAEALAFSDHMFTEARGSRLHKGV PQVLIVITDGESHDAEKLNTTAKALRDKGILVLAVGIAGANSWELLAMAGSSDKYYFVETFGGLKGIFSD VSASVCNSSKVDCEIEKVDLVFLMDGSNSIHPDDFQKMKGFLVSVVQDFDVSLNRVRIGVAQFSDSYRSE FLLGTFTGEREISTQIEGIQQIFGYTHIGDALRKVKYYFQPDMGSRINAGTPQVLLVLTDGRSQDEVAQA AEELRHKGVDIYSVGIGDVDDQELVQITGTAEKKLTVHNFDELKKVKKRIVRNICTSGGESNCFVDVVVG FDISSLQRGQTLLEGQPWMGSYLQDLLRAISSLNGVSCEVGTETQVSIAFQVTNAMERYPSKFEIYSENI LSSLQGVTVNGPSRLNANLLSSLWDTFQNKSAARGKVVLLFSDGLDDGIEKLEQKSDELRKEGLNALITI AVDGAADSSDLADLLYIEFGKGFEYRTQFTIGMRNLGSQLSRQLINVAERTCCCLLCKCTGGDGAMGDPG SAGKKGPPGFKGSDGYLGEEGIAGERGASGPMGEQGTKGCFGAKGPKGTRGLSGEEGEVGEDGLDGLDGE QGDHGIPGRRGEKGDEGSQGNPGRRGAAGDRGAKGLRGDPGTPGRDSSIQGPKGLKGDLGRQGRRGWPGS PGTPGSRRKMVVHGRRGHIGPQGNPGTPGPDGLAGSPGLRGPQGPRGEVGEKGEKGSLGMKGPQGPPGPG GQAGSQGHLGSQGNKGEPGDLGEKGAAGFPGPRGLQGDDGSPGYGSIGRKGTKGQEGFPGESGLKGDIGD PGDPGEAGPKGARGKTVSAGIPGEPGSPGEPGPPGRKGVKGARGLASFSTCDLIQYVRDHSPGRHGKPEC PVHPTELVFVLDQSRDVTEQDFERMKGMMVSLVRDVKVREANCPVGARVAILAYNSHTRHLIRFSDAYRK DQLLTAIKALPYERSSDSREIGKAMRFISRNVFKRTLPGAHVRRIATFFSSGPSADAQTITTAAMEFSAL DIVPVVIAFSNVPSVKRAFSIDDTGTFQVIVVPSGSDEGPALERLQRCTFCYDLCKPDASCDQAKPPPIQ SYLDTAFLLDGSRHVGSAEFEDMRDFLEALLDHFEITSEPETSVTGDRVALLSHAPLDFLPNTQRSPVRT EFNLTSYSSKRLMKRHVDQAVQQLHGDAFLGHALGWALDNVFLNTPNLRRNKVIFVISAGETSHLDAETL KKESLRAKCHGYALFVFSLGPDWDDKELEDLASHPVDQHLIQLGRIHKPDHGYSVKFVKSFINSIRHGIN KYPPVNLKAKCNRLGSRDLKPPPRQFRSFVPGPQKANLKDHTAEAAKLFQDKKRLSSMLKGGRATISSLS RSTRYAFKQGKEAIKATSKLGKRSA TRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
AscI-MluI
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_001102607 |
| ORF Size | 6795 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_001102607.1, NP_001096077.1 |
| RefSeq Size | 7098 bp |
| RefSeq ORF | 6798 bp |
| Locus ID | 245026 |
| UniProt ID | Q8C6K9 |
| Cytogenetics | 9 F1 |
| MW | 246.3 kDa |
| Gene Summary | Collagen VI acts as a cell-binding protein.[UniProtKB/Swiss-Prot Function] |
{kind=link}
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
{0} Product Review(s)
Be the first one to submit a review

