


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
CD44 Human Gene Knockout Kit (CRISPR)
CAT#: KN202455RB
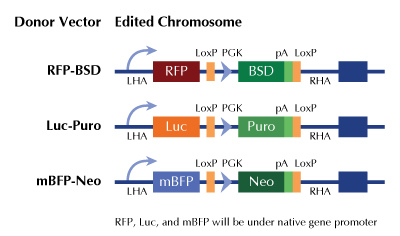
CD44 - human gene knockout kit via CRISPR, HDR mediated
Functional Cassette: GFP-puro Luciferase-Puro mBFP-Neo
HDR-mediated knockout kit validation
USD 1,657.00
2 Weeks*
Product Images
USD 450.00
USD 1,019.00
Specifications
| Product Data | |
| Format | 2 gRNA vectors, 1 RFP-BSD donor, 1 scramble control |
| Donor DNA | RFP-BSD |
| Symbol | CD44 |
| Locus ID | 960 |
| Components |
KN202455G1, CD44 gRNA vector 1 in pCas-Guide CRISPR vector, Target Sequence: GGCACTCACCGATCTGCGCC KN202455G2, CD44 gRNA vector 2 in pCas-Guide CRISPR vector, Target Sequence: AGTTTTGGTGGCACGCAGCC KN202455RBD, donor DNA containing left and right homologous arms and RFP-BSD functional cassette. Homologous arm and RFP-BSD sequences: pUC vector backbone in gray; Left arm sequence in blue; RFP-BSD in green; Right arm in violet AAGGCGAGTT ACATGATCCC CCATGTTGTG CAAAAAAGCG GTTAGCTCCT TCGGTCCTCC GATCGTTGTC AGAAGTAAGT TGGCCGCAGT GTTATCACTC ATGGTTATGG CAGCACTGCA TAATTCTCTT ACTGTCATGC CATCCGTAAG ATGCTTTTCT GTGACTGGTG AGTACTCAAC CAAGTCATTC TGAGAATAGT GTATGCGGCG ACCGAGTTGC TCTTGCCCGG CGTCAATACG GGATAATACC GCGCCACATA GCAGAACTTT AAAAGTGCTC ATCATTGGAA AACGTTCTTC GGGGCGAAAA CTCTCAAGGA TCTTACCGCT GTTGAGATCC AGTTCGATGT AACCCACTCG TGCACCCAAC TGATCTTCAG CATCTTTTAC TTTCACCAGC GTTTCTGGGT GAGCAAAAAC AGGAAGGCAA AATGCCGCAA AAAAGGGAAT AAGGGCGACA CGGAAATGTT GAATACTCAT ACTCTTCCTT TTTCAATATT ATTGAAGCAT TTATCAGGGT TATTGTCTCA TGAGCGGATA CATATTTGAA TGTATTTAGA AAAATAAACA AATAGGGGTT CCGCGCACAT TTCCCCGAAA AGTGCCACCT GACGTCTAAG AAACCATTAT TATCATGACA TTAACCTATA AAAATAGGCG TATCACGAGG CCCTTTCGGG TCGCGCGTTT CGGTGATGAC GGTGAAAACC TCTGACACAT GCAGCTCCCG TTGACGGTCA CAGCTTGTCT GTAAGCGGAT GCCGGGAGCA GACAAGCCCG TCAGGGCGCG TCAGCGGGTG TTGGCGGGTG TCGGGGCTGG CTTAACTATG CGGCATCAGA GCAGATTGTA CTGAGAGTGC ACCATAAAAT TGTAAACGTT AATATTTTGT TAAAATTCGC GTTAAATTTT TGTTAAATCA GCTCATTTTT TAACCAATAG GCCGAAATCG GCAAAATCCC TTATAAATCA AAAGAATAGC CCGAGATAGG GTTGAGTGTT GTTCCAGTTT GGAACAAGAG TCCACTATTA AAGAACGTGG ACTCCAACGT CAAAGGGCGA AAAACCGTCT ATCAGGGCGA TGGCCCACTA CGTGAACCAT CACCCAAATC AAGTTTTTTG GGGTCGAGGT GCCGTAAAGC ACTAAATCGG AACCCTAAAG GGAGCCCCCG ATTTAGAGCT TGACGGGGAA AGCCGGCGAA CGTGGCGAGA AAGGAAGGGA AGAAAGCGAA AGGAGCGGGC GCTAGGGCGC TGGCAAGTGT AGCGGTCACG CTGCGCGTAA CCACCACACC CGCCGCGCTT AATGCGCCGC TACAGGGCGC GTACTATGGT TGCTTTGACG TATGCGGTGT GAAATACCGC ACAGATGCGT AAGGAGAAAA TACCGCATCA GGCGCCATTC GCCATTCAGG CTGCGCAACT GTTGGGAAGG GCGATCGGTG CGGGCCTCTT CGCTATTACG CCAGCTGGCG AAAGGGGGAT GTGCTGCAAG GCGATTAAGT TGGGTAACGC CAGGGTTTTC CCAGTCACGA CGTTGTAAAA CGACGGCCAG TGAATTGGAG GCTACAGTCA GTGGAGAGGA CTTTCACAGG CTGTCGCCGT GCTCATTTGA TAACTGCCCG TTATTCATGC GACATCTCCA GCTCCTCTCC CAGGATATCC AACATCCTGT GAAACCCAGA GATCTTGCTC CAGCCGGATT CAGAGAAATT TAGCGGGAAA GGAGAGGCCA AAGGCTGAAC CCAATGGTGC AAGGTTTTAC GGTTCGGTCA TCCTCTGTCC TGACGCCGCG GGGCCAGCGG GAGAAGAAAG CCAGTGCGTC TCTGGGCGCA GGGGCCAGTG GGGCTCGGAG GCACAGGCAC CCCGCGACAC TCCAGGTTCC CCGACCCACG TCCCTGGCAG CCCCGATTAT TTACAGCCTC AGCAGAGCAC GGGGCGGGGG CAGAGGGGCC CGCCCGGGAG GGCTGCTACT TCTTAAAACC TCTGCGGGCT GCTTAGTCAC AGCCCCCCTT GCTTGGGTGT GTCCTTCGCT CGCTCCCTCC CTCCGTCTTA GGTCACTGTT TTCAACCTCG AATAAAAACT GCAGCCAACT TCCGAGGCAG CCTCATTGCC CAGCGGACCC CAGCCTCTGC CAGGTTCGGT CCGCCATCCT CGTCCCGTCC TCCGCCGGCC CCTGCCCCGC GCCCAGGGAT CCTCCAGCTC CTTTCGCCCG CGCCCTCCGT TCGCTCCGGA CACCTGGGCA GCAAGATGGG TGCGGGGTGC TCAGCGCGGA CCCGGCGGCA GCCCCTCCGG CTGAGTCGGC CCTGGGGGAC TGGAGTCAAG TGAGCTGTCT GCGAAGTGCA TTGGGCTCCG GAAAGCAGGG CTGGGATTTG CGCTAAACCG TTGGAGAATG TGTCTGTGGA AGCACCATTT GGTTGAAAGA AAAAGAGAAA GAGAAGAAAG TTTGTTGGGC AGGCTGCCGG CGCGCAGTTT TGGGCGAGGT CGCTAGAGCT GCAGCACATG GCAGAAAGTA ACCGTTCTCC CGGATGCGCA CAGTCGTTGT CTGGACTAAC AGGCTCCTGT GCCCAAGGGC TCGCCAAGCC CCACCGGGCT GTGTCTAGGC AGGGCAGAGC TGGGCGGGGC AGAGACTGGG GCTGGAACAG GGCGAGTGGC TGTTATCAAG GTGGTCACAG AAGGGATCAC AATTCCAAGT GTGAGACTAG CTGGCAATGG GTTTTCCAGA AAGGGGTCCT GGGTTCTCCC AGCTCCCCAC TGAGCCTTGT TCCAAAGCTT ACAGTCCGCA GTGTCACTGC CACCTTAGCG CTGTGGAAGC TTGAACCAGC TCTGCGGTGA GGTCTCACTC TCGCCGGTTG GACTTTAGAT CAGAAGGGAT CTTGCTGCCG CCCGAAAGAG GAAGGGCTGG AAGAGGAAGG AGCTTGGCGT AATCATGGTC ATAGCTGTTT CCTGTGTGAA ATTGTTATCC GCTCACAATT CCACACAACA TACGAGCCGG AAGCATAAAG TGTAAAGCCT GGGGTGCCTA ATGAGTGAGC TAACTCACAT TAATTGCGTT GCGCTCACTG CCCGCTTTCC AGTCGGGAAA CCTGTCGTGC CAGCTGCATT AATGAATCGG CCAACGCGCG GGGAGAGGCG GTTTGCGTAT TGGGCGCTCT TCCGCTTCCT CGCTCACTGA CTCGCTGCGC TCGGTCGTTC GGCTGCGGCG AGCGGTATCA GCTCACTCAA AGGCGGTAAT ACGGTTATCC ACAGAATCAG GGGATAACGC AGGAAAGAAC ATGTGAGCAA AAGGCCAGCA AAAGGCCAGG AACCGTAAAA AGGCCGCGTT GCTGGCGTTT TTCCATAGGC TCCGCCCCCC TGACGAGCAT CACAAAAATC GACGCTCAAG TCAGAGGTGG CGAAACCCGA CAGGACTATA AAGATACCAG GCGTTTCCCC CTGGAAGCTC CCTCGTGCGC TCTCCTGTTC CGACCCTGCC GCTTACCGGA TACCTGTCCG CCTTTCTCCC TTCGGGAAGC GTGGCGCTTT CTCATAGCTC ACGCTGTAGG TATCTCAGTT CGGTGTAGGT CGTTCGCTCC AAGCTGGGCT GTGTGCACGA ACCCCCCGTT CAGCCCGACC GCTGCGCCTT ATCCGGTAAC TATCGTCTTG AGTCCAACCC GGTAAGACAC GACTTATCGC CACTGGCAGC AGCCACTGGT AACAGGATTA GCAGAGCGAG GTATGTAGGC GGTGCTACAG AGTTCTTGAA GTGGTGGCCT AACTACGGCT ACACTAGAAG AACAGTATTT GGTATCTGCG CTCTGCTGAA GCCAGTTACC TTCGGAAAAA GAGTTGGTAG CTCTTGATCC GGCAAACAAA CCACCGCTGG TAGCGGTGGT TTTTTTGTTT GCAAGCAGCA GATTACGCGC AGAAAAAAAG GATCTCAAGA AGATCCTTTG ATCTTTTCTA CGGGGTCTGA CGCTCAGTGG AACGAAAACT CACGTTAAGG GATTTTGGTC ATGAGATTAT CAAAAAGGAT CTTCACCTAG ATCCTTTTAA ATTAAAAATG AAGTTTTAAA TCAATCTAAA GTATATATGA GTAAACTTGG TCTGACAGTT ACCAATGCTT AATCAGTGAG GCACCTATCT CAGCGATCTG TCTATTTCGT TCATCCATAG TTGCCTGACT CCCCGTCGTG TAGATAACTA CGATACGGGA GGGCTTACCA TCTGGCCCCA GTGCTGCAAT GATACCGCGA GAACCACGCT CACCGGCTCC AGATTTATCA GCAATAAACC AGCCAGCCGG AAGGGCCGAG CGCAGAAGTG GTCCTGCAAC TTTATCCGCC TCCATCCAGT CTATTAATTG TTGCCGGGAA GCTAGAGTAA GTAGTTCGCC AGTTAATAGT TTGCGCAACG TTGTTGCCAT TGCTACAGGC ATCGTGGTGT CACGCTCGTC GTTTGGTATG GCTTCATTCA GCTCCGGTTC CCAACGATCGE100003, scramble sequence in pCas-Guide vector |
| Disclaimer | These products are manufactured and supplied by OriGene under license from ERS. The kit is designed based on the best knowledge of CRISPR technology. The system has been functionally validated for knocking-in the cassette downstream the native promoter. The efficiency of the knock-out varies due to the nature of the biology and the complexity of the experimental process. |
| Reference Data | |
| RefSeq | NM_000610, NM_001001389, NM_001001390, NM_001001391, NM_001001392, NM_001202555, NM_001202556, NM_001202557 |
| UniProt ID | P16070 |
| Synonyms | CDW44; CSPG8; ECMR-III; HCELL; HUTCH-I; IN; LHR; MC56; MDU2; MDU3; MIC4; Pgp1 |
| Summary | The protein encoded by this gene is a cell-surface glycoprotein involved in cell-cell interactions, cell adhesion and migration. It is a receptor for hyaluronic acid (HA) and can also interact with other ligands, such as osteopontin, collagens, and matrix metalloproteinases (MMPs). This protein participates in a wide variety of cellular functions including lymphocyte activation, recirculation and homing, hematopoiesis, and tumor metastasis. Transcripts for this gene undergo complex alternative splicing that results in many functionally distinct isoforms, however, the full length nature of some of these variants has not been determined. Alternative splicing is the basis for the structural and functional diversity of this protein, and may be related to tumor metastasis. [provided by RefSeq, Jul 2008] |
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| KN202455 | CD44 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN202455BN | CD44 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN202455LP | CD44 - human gene knockout kit via CRISPR, HDR mediated |
USD 1,657.00 |
|
| KN402455 | CD44 - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated. |
USD 1,657.00 |
|
| GA100682 | CD44 CRISPRa kit - CRISPR gene activation of human CD44 molecule (Indian blood group) |
USD 1,657.00 |
{0} Product Review(s)
Be the first one to submit a review