


















































 Islands")


















































")






")
















































")
























































































")
")





 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
CHST15 Human Gene Knockout Kit (CRISPR)
CAT#: KN406489
CHST15 - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated.
KN2.0 knockout kit validation
USD 1,657.00
2 Weeks*
Product Images
USD 450.00
USD 522.00
Specifications
| Product Data | |
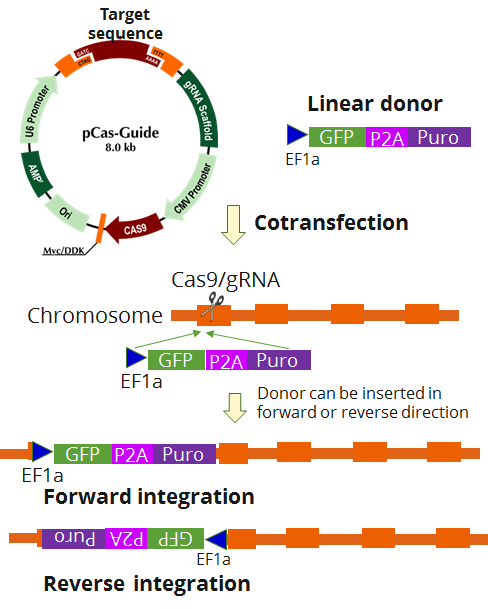
| Format | 2 gRNA vectors, 1 linear donor |
| Donor DNA | EF1a-GFP-P2A-Puro |
| Symbol | CHST15 |
| Locus ID | 51363 |
| Components |
KN406489G1, CHST15 gRNA vector 1 in pCas-Guide CRISPR vector KN406489G2, CHST15 gRNA vector 2 in pCas-Guide CRISPR vector KN406489D, Linear donor DNA containing LoxP-EF1A-tGFP-P2A-Puro-LoxP: The sequence below is cassette sequence only. The linear donor DNA also contains proprietary target sequence. LoxP-EF1A-tGFP-P2A-Puro-LoxP (2739 bp) ATAACTTCGT ATAATGTATG CTATACGAAG TTATCGTGAG GCTCCGGTGC CCGTCAGTGG GCAGAGCGCA CATCGCCCAC AGTCCCCGAG AAGTTGGGGG GAGGGGTCGG CAATTGAACC GGTGCCTAGA GAAGGTGGCG CGGGGTAAAC TGGGAAAGTG ATGTCGTGTA CTGGCTCCGC CTTTTTCCCG AGGGTGGGGG AGAACCGTAT ATAAGTGCAG TAGTCGCCGT GAACGTTCTT TTTCGCAACG GGTTTGCCGC CAGAACACAG GTAAGTGCCG TGTGTGGTTC CCGCGGGCCT GGCCTCTTTA CGGGTTATGG CCCTTGCGTG CCTTGAATTA CTTCCACCTG GCTGCAGTAC GTGATTCTTG ATCCCGAGCT TCGGGTTGGA AGTGGGTGGG AGAGTTCGAG GCCTTGCGCT TAAGGAGCCC CTTCGCCTCG TGCTTGAGTT GAGGCCTGGC CTGGGCGCTG GGGCCGCCGC GTGCGAATCT GGTGGCACCT TCGCGCCTGT CTCGCTGCTT TCGATAAGTC TCTAGCCATT TAAAATTTTT GATGACCTGC TGCGACGCTT TTTTTCTGGC AAGATAGTCT TGTAAATGCG GGCCAAGATC TGCACACTGG TATTTCGGTT TTTGGGGCCG CGGGCGGCGA CGGGGCCCGT GCGTCCCAGC GCACATGTTC GGCGAGGCGG GGCCTGCGAG CGCGGCCACC GAGAATCGGA CGGGGGTAGT CTCAAGCTGG CCGGCCTGCT CTGGTGCCTG GCCTCGCGCC GCCGTGTATC GCCCCGCCCT GGGCGGCAAG GCTGGCCCGG TCGGCACCAG TTGCGTGAGC GGAAAGATGG CCGCTTCCCG GCCCTGCTGC AGGGAGCTCA AAATGGAGGA CGCGGCGCTC GGGAGAGCGG GCGGGTGAGT CACCCACACA AAGGAAAAGG GCCTTTCCGT CCTCAGCCGT CGCTTCATGT GACTCCACGG AGTACCGGGC GCCGTCCAGG CACCTCGATT AGTTCTCGAG CTTTTGGAGT ACGTCGTCTT TAGGTTGGGG GGAGGGGTTT TATGCGATGG AGTTTCCCCA CACTGAGTGG GTGGAGACTG AAGTTAGGCC AGCTTGGCAC TTGATGTAAT TCTCCTTGGA ATTTGCCCTT TTTGAGTTTG GATCTTGGTT CATTCTCAAG CCTCAGACAG TGGTTCAAAG TTTTTTTCTT CCATTTCAGG TGTCGTGAAT GGAGAGCGAC GAGAGCGGCC TGCCCGCCAT GGAGATCGAG TGCCGCATCA CCGGCACCCT GAACGGCGTG GAGTTCGAGC TGGTGGGCGG CGGAGAGGGC ACCCCCGAGC AGGGCCGCAT GACCAACAAG ATGAAGAGCA CCAAAGGCGC CCTGACCTTC AGCCCCTACC TGCTGAGCCA CGTGATGGGC TACGGCTTCT ACCACTTCGG CACCTACCCC AGCGGCTACG AGAACCCCTT CCTGCACGCC ATCAACAACG GCGGCTACAC CAACACCCGC ATCGAGAAGT ACGAGGACGG CGGCGTGCTG CACGTGAGCT TCAGCTACCG CTACGAGGCC GGCCGCGTGA TCGGCGACTT CAAGGTGATG GGCACCGGCT TCCCCGAGGA CAGCGTGATC TTCACCGACA AGATCATCCG CAGCAACGCC ACCGTGGAGC ACCTGCACCC CATGGGCGAT AACGATCTGG ATGGCAGCTT CACCCGCACC TTCAGCCTGC GCGACGGCGG CTACTACAGC TCCGTGGTGG ACAGCCACAT GCACTTCAAG AGCGCCATCC ACCCCAGCAT CCTGCAGAAC GGGGGCCCCA TGTTCGCCTT CCGCCGCGTG GAGGAGGATC ACAGCAACAC CGAGCTGGGC ATCGTGGAGT ACCAGCACGC CTTCAAGACC CCGGATGCAG ATGCCGGTGA AGAAAGAGGA AGCGGAGCTA CTAACTTCAG CCTGCTGAAG CAGGCTGGAG ACGTGGAGGA GAACCCTGGA CCTATGACCG AGTACAAGCC CACGGTGCGC CTCGCCACCC GCGACGACGT CCCCAGGGCC GTACGCACCC TCGCCGCCGC GTTCGCCGAC TACCCCGCCA CGCGCCACAC CGTCGATCCG GACCGCCACA TCGAGCGGGT CACCGAGCTG CAAGAACTCT TCCTCACGCG CGTCGGGCTC GACATCGGCA AGGTGTGGGT CGCGGACGAC GGCGCCGCGG TGGCGGTCTG GACCACGCCG GAGAGCGTCG AAGCGGGGGC GGTGTTCGCC GAGATCGGCC CGCGCATGGC CGAGTTGAGC GGTTCCCGGC TGGCCGCGCA GCAACAGATG GAAGGCCTCC TGGCGCCGCA CCGGCCCAAG GAGCCCGCGT GGTTCCTGGC CACCGTCGGC GTCTCGCCCG ACCACCAGGG CAAGGGTCTG GGCAGCGCCG TCGTGCTCCC CGGAGTGGAG GCGGCCGAGC GCGCCGGGGT GCCCGCCTTC CTGGAGACCT CCGCGCCCCG CAACCTCCCC TTCTACGAGC GGCTCGGCTT CACCGTCACC GCCGACGTCG AGGTGCCCGA AGGACCGCGC ACCTGGTGCA TGACCCGCAA GCCCGGTGCC TGAAACTTGT TTATTGCAGC TTATAATGGT TACAAATAAA GCAATAGCAT CACAAATTTC ACAAATAAAG CATTTTTTTC ACTGCATTCT AGTTGTGGTT TGTCCAAACT CATCAATGTA TCTTAATAAC TTCGTATAAT GTATGCTATA CGAAGTTAT
|
| Disclaimer | These products are manufactured and supplied by OriGene under license from ERS. The kit is designed based on the best knowledge of CRISPR technology. The system has been functionally validated for knocking-in the cassette downstream the native promoter. The efficiency of the knock-out varies due to the nature of the biology and the complexity of the experimental process. |
| Reference Data | |
| RefSeq | NM_001270764, NM_001270765, NM_014863, NM_015892 |
| UniProt ID | Q7LFX5 |
| Synonyms | BRAG; GALNAC4S-6ST |
| Summary | Chondroitin sulfate (CS) is a glycosaminoglycan which is an important structural component of the extracellular matrix and which links to proteins to form proteoglycans. Chondroitin sulfate E (CS-E) is an isomer of chondroitin sulfate in which the C-4 and C-6 hydroxyl groups are sulfated. This gene encodes a type II transmembrane glycoprotein that acts as a sulfotransferase to transfer sulfate to the C-6 hydroxal group of chondroitin sulfate. This gene has also been identified as being co-expressed with RAG1 in B-cells and as potentially acting as a B-cell surface signaling receptor. Alternative splicing results in multiple transcript variants encoding distinct isoforms. [provided by RefSeq, Jul 2012] |

Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| GA109764 | CHST15 CRISPRa kit - CRISPR gene activation of human carbohydrate sulfotransferase 15 |
USD 1,657.00 |
{0} Product Review(s)
Be the first one to submit a review